With the release of VSAN, VMware fulfills the true software-defined
data center with the combination of virtualized compute, network and
storage. After VSAN release, I will definitely say that buying storage
for your infrastructure is not only limited to the storage vendors but
also VSAN will play a major role because which is part of hypervisor
after vSphere 5.5 Update 1 onwards. Virtual SAN 5.5 is a new
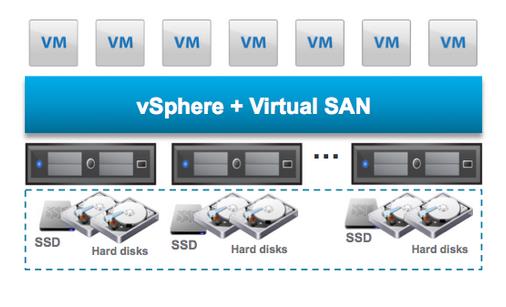
hypervisor-converged storage tier that extends the vSphere hypervisor to
pool server-side magnetic disks (HDDs) and solid-state drives (SSDs).
By clustering server-side HDDs and SSDs, Virtual SAN creates a
distributed shared datastore designed and optimized for virtual
environments.Virtual SAN is a standalone product that is sold separate
from vSphere and requires its own license key.
Minimum Requirements for VSAN:
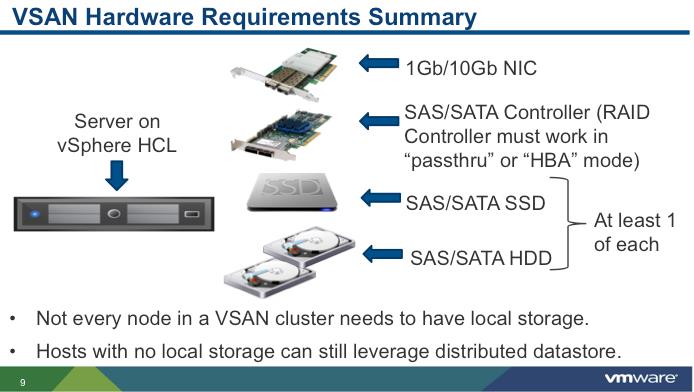
Minimum of 3 ESXi 5.5 hosts with all contributing local disks (1 SSD and 1 HDD) to VSAN cluster
Minimum 4 GB of RAM for ESXi host
ESXi host should be managed by vCenter Server 5.5 and It should be configured as Virtual SAN cluster
Each ESXi host must have minimum of single 1 Gb Ethernet adapter available solely for the use of virtual SAN
At least 1 SAS or SATA solid state Drive (SSD) should be part of
each ESXi host with SSD is not claimed by vSphere Flash Read Cache
VSAN Scalability:
VSAN with GA release, It supports around 32 Hosts, 3200 Virtual
Machines, 2M Iops and 4.4 petabytes. It is really scalable and provides
the scalability as like an enterprise storage.
How to Download VSAN:
As already explained, VSAN is included with he hypervisor form
vSphere 5.5 Update 1. So download ESXi 5.5 Update 1 and vCenter server
5.5 Update 1 to use the VSAN. Log in or sign-up with your VMware account
and download.
VMware provides the choice for the customers and partners to define
a VSAN solution either building your own node via components on our VMware compatibility guide for VSAN
or Selecting VSAN read node. A Virtual SAN Ready Node is a predefined
combination of server hardware while a Ready Block is a predefined set
of servers for use with VMware Virtual SAN. Configurations are based on
server vendor validated configurations that include specific HDD, Flash
and IO Controller components certified for Virtual SAN, and available on
the VMware Compatibility Guide.
VSAN License and Prizing:
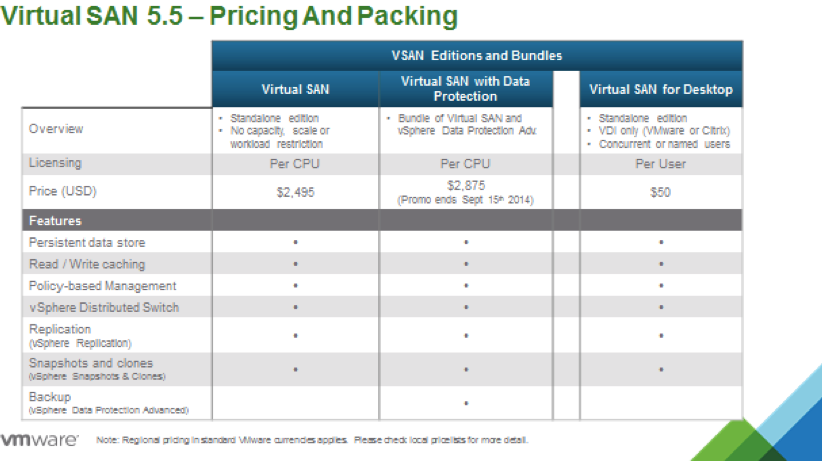
Below is the details about VSAN Prizing and Packaging. Below are the list of VSAN editions and bundles
VMware Virtual SAN Standalone
VMware Virtual SAN for Desktops
VMware Virtual SAN with Data Protection
VSA Upgrade Bundle + vSAN with Data Protection (End Date: 9/15/2014)
We will explain step by step VSAN configuration in upcoming posts but
I would like bring here the excellent demo walkthrough for VSAN from
VMware. It gives the step by Step walkthrough for the each below
mentioned configuration items.
It can be easliy checked using hardware managenet tools like HP
system Management, HP ILO or even in Hardware status tab of ESXi host
from vSphere Client. This post talks about the checking the status of
disk failures for esxi host command line utilities. In this post, i am
going to discuss about the HP hardware’s and how to check the disk
failures from command line in Hp hardware’s. This post will guide you
step by step procedure to verify the disk status in ESXi host using
HPSSACLI utility which is part of HP ESXi Utilities Offline bundle for
VMware ESXi 5.x.
HP ESXi Utilities Offline bundle for VMware ESXi 5.x will be
available as part of HP customized ESXi installer image but if it is not
a HP customized ESXi image then you may need to download and install HP
ESXi Utilities Offline bundle for VMware ESXi 5.x.This ZIP file
contains 3 different utilities HPONCFG , HPBOOTCFG and HPSSACLI
utilities for remote online configuration of servers.
HPONCFG — Command line utility used for obtaining and setting ProLiant iLO configurations.
HPBOOTCFG — Command line utility used for configuring ProLiant server boot order.
HPSSACLI – Command line utility used for configuration and diagnostics of ProLiant server SmartArrays.
You can download and install HP ESXi utilities offline bundle for ESXi 5.X using below command esxcli software vib install -f -v /tmp/hp-esxi5.5uX-bundle-1.7-13.zip
You can even directly donwload HPSSACLI utility and Upload the VIB file into your ESXi host and execute the below command to install the HPACUCLI utility. esxcli software vib install -f -v /tmp/hpssacli-1.60.17.0-5.5.0.vib
Once it is installed. Browse towards the directory /opt/hp/hpssacli/bin and verify the installation.
Check the Disk Failure Status:
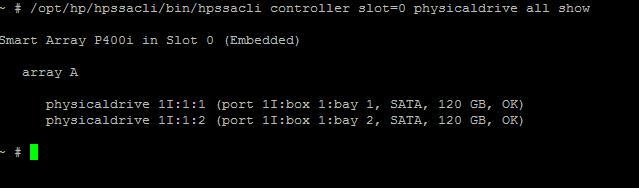
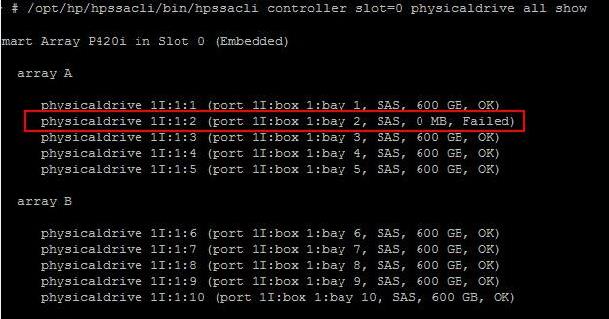
Type the below command to check the status of Disks in your ESXi
host. It displays the status of the Disk in All Arrays under the
Controller. /opt/hp/hpssacli/bin/hpssacli controller slot=0 physicaldrive all show
Thats
it. We identified the disk failure, You may need to generate the HP ADU
(Array Diagnostics Utility) report to raise the support case with
hardware vendor.
A conceptual look at how CoreOS works with Docker to create containerized apps.
CoreOS uses Docker to deploy applications in virtual containers; it also
features a management communications bus, and group instance
management.
Rackspace, Amazon Web Services (AWS), GoogleComputeEngine (GCE), and
Brightbox are early cloud compute providers compatible with CoreOS and
with specific deployment capacity for CoreOS. We tried Rackspace and
AWS, and also some local “fleet” deployments.
CoreOS is skinny. We questioned its claims of less overall memory used,
and wondered if it was stripped to the point of uselessness. We found
that, yes, it saves a critical amount of memory (for some), and no, it’s
tremendously Spartan, but pretty useful in certain situations.
CoreOS has many similarities with Ubuntu.
They’re both free and GPLv3 licensed. Ubuntu 14.04 and CoreOS share the
same kernel. Both are easily customizable, and no doubt you can make
your own version. But CoreOS shuns about half of the processes that
Ubuntu attaches by default.
If you’re a critic of the bloatware inside many operating systems
instances, CoreOS might be for you. In testing, we found it highly
efficient. It’s all Linux kernel-all-the-time, and if your organization
is OS-savvy, you might like what you see in terms of performance and
scale.
Security could be an issue
CoreOS uses curl for communications and SSL, and we recommend
adding a standard, best-practices external SSL certificate authority for
instance orchestration. Otherwise, you'll be madly generating and
managing SSL relationships among a dynamic number of instances. CoreOS
sends updates using signed certificates, too.
With this added SSL security control, your ability to scale efficiently
is but a few scripts away. Here’s the place where your investment in SSL
certs and chains of authority back to a root cert is a good idea. It
adds to the overhead, of course, to use SSL for what might otherwise be
considered “trivial” instances. All the bits needed for rapid secure
communications with SSL are there, and documented, and wagged in your
face. Do it.
What You Get
CoreOS is a stripped-down Linux distro designed for rapidly deployed
Spartan instance use. The concept is to have a distro that’s bereft of
the usual system memory and daemon leeches endemic to popular
distributions and “ecosystems.’’ This is especially true as popular
distros get older and more “feature packed”.
More available memory usually means more apps that can be run, and
CoreOS is built to run them in containers. Along with its own
communications bus—primitive as it is— you get to run as many instances
(and apps) as possible with the least amount of overhead and management
drama.
For those leaning towards containerized instances, it blasts them in a
controlled procedure, then monitors them for health. It’s not tough to
manage the life cycle of a CoreOS instance. RESTful commands do much of
the heavy lifting.
Inside CoreOS is a Linux kernel, LXC capacity, and the etcd/etcd daemon
service discovery/control daemon, along with Docker, the application
containerization system, and systemd—the start/stop process controller
that’s replaced various initd (initial daemon) in many distros.
There is multiple instance management using fleet—a key benefit for those primarily starting pools and even oceans of instances of apps/OS instances on a regular basis.
Like Ubuntu and RedHat, it uses the systemd daemon as an interface
control mechanism, and it’s up to date with the same kernel used by
Ubuntu 14.04 and RedHat EL7. Many of your updated systemd-based scripts
will work without changes.
The fleetd is controlled by the user space command fleetctl and it
instantiates processes, and the etcd daemon is a service discovery (like
a communications bus) using etcdctl for monitoring—all at a low level
and CLI-style.
The etcd is used to accept REST commands, using simple verbs. It uses a
RESTful API set, and it’s not Puppet, Chef, or other service bus
communications bus controller, but a lean/tight communications
methodology. It works and is understandable by Unix/Linux coders and
admins.
A downside is that container and instance sprawl become amazingly easy.
You can fire instances, huge number of them, at will. There aren’t any
clever system-wide monitoring mechanisms that will warn you that your
accounting department will simply explode when they see your sprawl bill
on AWS or GCE. Teardown isn’t enforced—but it’s not tough to do.
We did a test to determine the memory differences between Ubuntu 14.04
and CoreOS, configuring each OS as 1GB memory machines on the same
platform. They reported the same kernel (Linux 3.12), and were used with
default settings.
We found roughly 28% to 44% more memory available for apps with CoreOS —
before "swap" started churning the CPU/memory balances within the state
machine.
This means an uptake in speed of execution for apps until they need I/O
or other services, less memory churn and perhaps greater cache hits.
Actual state machine performance improvements are dependent on how the
app uses the host but we feel that the efficiencies of memory use and
overall reduction in bloat (and security attack surface potential) are
worth the drill.
These results were typical across AWS, GCE, and our own hosted platform
that ran on a 60-core HP DL-580 Gen8. The HP server used could probably
handle several hundred instances if we expanded the server’s memory to
its 6TB max—not counting Docker instances.
We could easily bring up a fleet of CoreOS instances, control it, feed
it containers with unique IDs and IPs, make the containers do work (we
did not exercise the containers), then shut them down, mostly with shell
scripts rather than direct commands.
The suggested scripts serve as a template, and more templates are
appearing, that allowed us to easily replicate functionality, so as to
manage sprawl. If you’re looking for instrumentation, get some glitzy UI
elsewhere, and the same goes for high-vocabulary communications
infrastructure.
Once you start adding daemons and widgetry, you’re back to Ubuntu or RedHat.
And we warn that we could also make mistakes that were unrecoverable
with equally high speed, and remind that there aren’t any real
safeguards except syntax checking, and the broad use of SSL keys.
You can make hundreds of OS instances, each with perhaps 100 Docker
container apps all moving hopefully in a harmonious way. Crypt is used,
which means you need your keys ready to submit to become su/root.
Otherwise, you’re on your own.
Summary
This is a skinny instance, bereft of frills and daemons-with-no-use. We
found more memory and less potential for speed-slowing memory churn.
Fewer widgets and daemonry also means a smaller attack surface. No bloat
gives our engineer’s instinctual desire to match resources with
needs—no more and no less—more glee.
CoreOS largely means self-support, your own instrumentation, plentiful
script building, and liberation from the pomposity and fatuousness of
highly featured, general purpose, compute-engines.
 Minimum Requirements for VSAN:
Minimum Requirements for VSAN: